Experiment Automation
Overview
Ansible is the recommended tool for experiment automation. This guide will go over the basics of using Ansible for Merge experiments. The general Ansible docs can be found here.
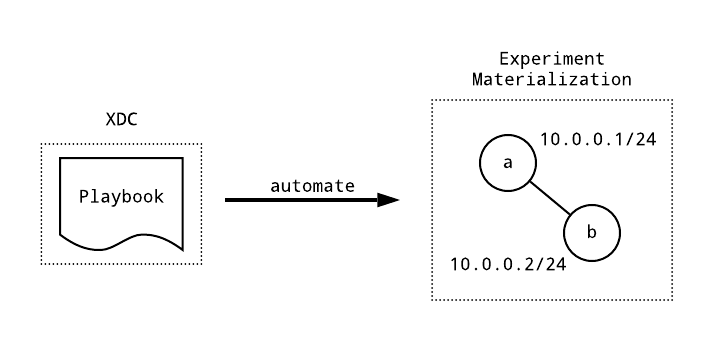
While playbooks can be executed from your local workstation using the XDC as a jump host to reach your nodes, we recommend executing playbooks directly from the XDC. This guide assumes you have created an XDC and attached your XDC to a materialization.
Prerequisites
Install Ansible in your XDC as follows:
sudo apt -y update
sudo apt -y install ansible
Topology
The following topology will be used in this example. It’s the simple two node topology depicted in the diagram above.
from mergexp import *
net = Network('ansible')
nodes = a, b = [net.node(name) for name in ['a', 'b']]
link = net.connect(nodes)
link[a].socket.addrs = ip4('10.0.0.1/24')
link[b].socket.addrs = ip4('10.0.0.2/24')
experiment(net)
Playbooks
A playbook is a sequence of plays that can be anything from provisioning users,
copying files, configuring software to running generic shell commands and
scripts. Here is an example of a playbook that installs and runs the iperf3
network performance tool across two nodes. Here we assume the nodes are called
named a and b and that the experiment network IP addresses of these nodes
are 10.0.0.1 and 10.0.0.2 respectively.
playbook.yml
- hosts: all
become: true
tasks:
- name: install iperf3
apt:
name: iperf3
- hosts: b
tasks:
- name: run iperf3 in server mode
shell: iperf3 --server --daemon --one-off
- hosts: a
tasks:
- name: run iperf3 in client mode
shell: iperf3 -c 10.0.0.2 --logfile /tmp/results
- name: collect results
fetch:
src: /tmp/results
dest: results
flat: yes
Inventories
Ansible requires a file called an inventory to tell it how to reach the nodes
it’s automating. This file is typically called hosts. Here is an example for
our two node topology.
hosts
[all]
a
b
Names in square brackets indicate groups, the names below the square brackets are the members of a
group. The all group was used in the first sequence of plays above, and then individual nodes were
used for the follow-on play sequences.
Note
The command line tool mrg is installed on all XDCs.
If this is the first time you’re using mrg on any XDC, you will need to configure it to contact
the correct portal via mrg config set server [server]. For example, grpc.sphere-testbed.net.
This only needs to be done once as configuration is stored in your home
directory and your home directory is mounted on all XDCs.
And in order to use mrg, you need to login via mrg login [username] from within the XDC. This
authenticates you to the portal and creates a time-limited session in which you can run mrg commands.
You should be able to retrieve a very basic inventory from the XDC using the mrg CLI. Assuming
your materialization is named ansible.hello.murphy, you would generate this as follows:
mrg nodes generate inventory ansible.hello.murphy > hosts
Configuration
Ansible configuration is kept in a file called ansible.cfg. This file can be configured globally
at /etc/ansible/ansible.cfg; it can be placed in your home directory at $HOME/.ansible.cfg for
all playbooks run by your user; or it can be placed in the local directory where you execute a
playbook from to affect only that playbook. There are a few options that are very useful to set for
executing from an XDC.
[defaults]
# don't check experiment node keys, if this is not set, you will have to
# explicitly accept the SSH key for each experiment node you run Ansible
# against
host_key_checking = False
# configure up to 5 hosts in parallel
forks = 5
# tmp directory on the local non-shared filesystem. Useful when running ansible
# on multiple separate XDCs
local_tmp = /tmp/ansible/tmp
[ssh_connection]
# connection optimization that increases speed significantly
pipelining = True
# control socket directory on the local non-shared filesystem. Useful when
# running ansible on multiple separate XDCs
control_path_dir = /tmp/ansible/cp
Execution
To execute the playbook.yml above we simply type
ansible-playbook -i hosts playbook.yml
Tip
Placing the inventory at location/etc/ansible/hosts causes ansible to use it
by default (without requiring the -i command line option for inventory). You can also
alter this location in your ansible.cfg file.After executing the playbook, you should have a results file in your local directory like the following
$ cat results
Connecting to host 10.0.0.2, port 5201
[ 6] local 10.0.0.1 port 40620 connected to 10.0.0.2 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 6] 0.00-1.00 sec 114 MBytes 954 Mbits/sec 0 437 KBytes
[ 6] 1.00-2.00 sec 113 MBytes 947 Mbits/sec 0 437 KBytes
[ 6] 2.00-3.00 sec 112 MBytes 941 Mbits/sec 0 437 KBytes
[ 6] 3.00-4.00 sec 112 MBytes 942 Mbits/sec 0 482 KBytes
[ 6] 4.00-5.00 sec 112 MBytes 941 Mbits/sec 0 482 KBytes
[ 6] 5.00-6.00 sec 111 MBytes 929 Mbits/sec 75 400 KBytes
[ 6] 6.00-7.00 sec 112 MBytes 943 Mbits/sec 0 426 KBytes
[ 6] 7.00-8.00 sec 113 MBytes 945 Mbits/sec 0 426 KBytes
[ 6] 8.00-9.00 sec 112 MBytes 941 Mbits/sec 0 426 KBytes
[ 6] 9.00-10.00 sec 113 MBytes 946 Mbits/sec 0 426 KBytes
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 6] 0.00-10.00 sec 1.10 GBytes 943 Mbits/sec 75 sender
[ 6] 0.00-10.04 sec 1.09 GBytes 937 Mbits/sec receiver
Optimizations
If you are running a larger experiment, or if you need to optimize your ansible runs, you can change some ansible configuration options to try and reduce ansible’s memory load on the XDC, such as caching your hosts’ facts in a json file.
[defaults]
# fact caching to file instead of in memory
fact_caching = jsonfile
# set directory/location of fact cache files
fact_caching_connection = /tmp/.ansible/fc
# ask ansible to gather facts only when necessary
gathering = smart
OpenSSH command update
It is a relatively small optimization, but you can ask ssh to try your ssh keys before any other authentication types.
[ssh_connection]
# add 'PreferredAuthentication' option
ssh_args = -C -o PreferredAuthentications=publickey -o ControlMaster=auto -o ControlPersist=60s
Timing analysis callbacks
If you want to try to do some analysis on your execution times or other ansible functions, you can turn on callbacks in the configuration file and get a additional information. See ansible documentation: callbacks:profile_tasks.
You can see what callback plugins are available on your host via
ansible-doc -t callback -l. profile_tasks, role_tasks, and timer are the
plugins you’re looking for.
Callbacks may also take some time, so feel free to turn them back off once you are no longer in need of timing analysis.
[defaults]
# examine timing for tasks
callback_whitelist = profile_tasks, timer
Host grouping and role assignment
Host grouping is another effective optimization technique that can be utilized from your playbook via inventory group and utilization of roles.
An example of a play running roles against a group of servers:
- name: apply all settings to host group target_servers
hosts: target_servers
become: yes
roles:
- generic_hosts_configuration
- target_server_packages
- make_target_servers_ready
This kind of role grouping is useful to keep ansible working on the same set of hosts through several sets of changes.
Additionally, if you have a set of tasks or a role where there is no ordering
necessary between hosts, you can specify an alternative “strategy”. Strategies
are discussed
minimally
in the ansible documentation, but available strategy
plugins and
their descriptions are available via the command ansible-doc -t strategy -l
(list) and ansible-doc -t strategy <strategy name>. You may wish to explore the
host_pinned or free strategies.
Tip
Groups can be created in your experiment MX files, and inventories reflecting those groups can be extracted using the CLI. See the Groups subection of the Model reference guide and the Config generation section of the CLI reference guide for more information.Asynchronous tasks
You can run long-running tasks “in the background” using ansible’s asynchronous task handler. This is a bit of a complex topic, so it is suggested to read the available documentation in its entirety before attempting asynchronous tasks, and it is very important to keep in mind that future tasks depending on asynchronous tasks must wait for them or risk play failure.
Python Dependencies
Many people use a tool called pip to install python packages, and ansible
includes a built-in pip package management module, however, using pip
as a package manager is several times slower than using the system-level package
manager (that is, yum/dnf or apt). If you have python package dependencies,
try searching the system package managers for those dependencies to see if the
version available to the system is acceptable for your use. If so, you can
install them using the system-level packager and reduce play wait time for pip.
Grouping the system packager installs into existing system packager plays also
reduces ansible play run times.
Note: Pypi is currently limiting pip’s access to xmlrpc calls (it is disallowed). There is a chance that pip installation will be unavailable or limited in the future.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.