Materialization Status is Ready!
Materialization status is ready! So, here’s an overview of what it looks like, what it means, and its limitations.
What status currently looks like
Overview
On the materializations page, you’ll now see that the table listing all materializations has three new fields:
- Created
- Last Updated
- Status

Tip
Note that this page does not automatically update, so you’ll need to manually refresh the page if you want the table to be updated.Status isn't retroactively applied
Unfortunately, materializations created before this feature was rolled out will have an Error message because the requisite metadata to get the status tree doesn’t exist.

When viewing the detailed status of these kinds of materializations, you’ll see:

Pre-existing materializations should still be running in whatever state it was running beforehand, but a proper status will not be available until you rematerialize!
Detailed Status View
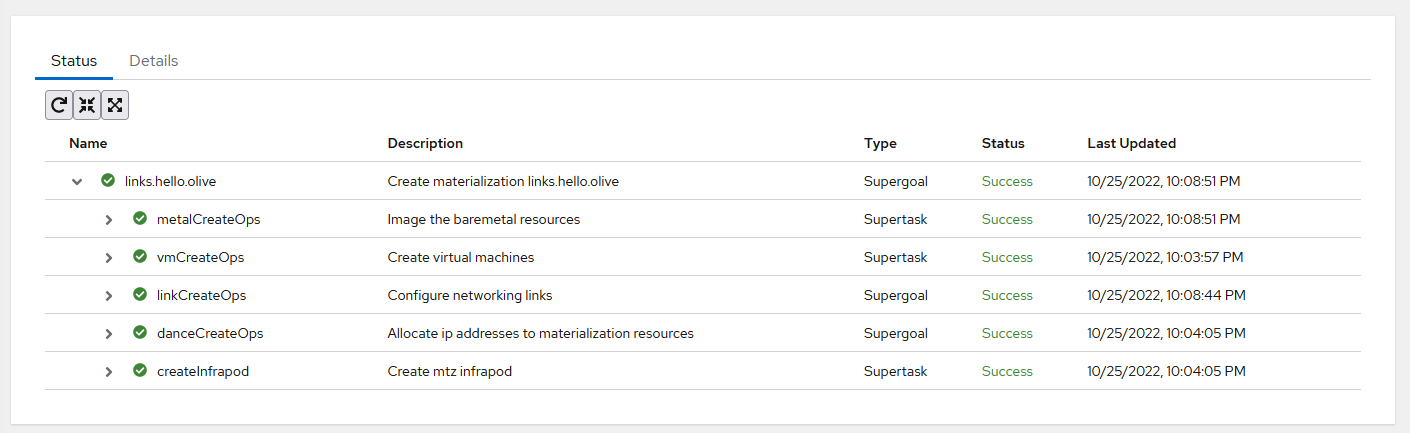
For materializations created after this feature was rolled out, when you click on it, you’ll now be greeted to a new page that shows the status materialization and all of its subtasks.
Tip
This page does automatically update, but the rate depends on the size of your materialization, since the status tree is recomputed from scratch every time. You can press the built-in refresh button if you want to manually fetch the latest statuses.For organizational purposes, it’s grouped into a tree-table. Here is what each Type means:
| Type | Description |
|---|---|
| Supergoals | The high level things we want to accomplish. |
| Supertasks | Collections of tasks that represent a single goal |
| Tasks | The individual tasks that are actually executed. |
Every entry contains a status value, and the highest priority status value is propagated up the tree. As “Success” has the lowest priority, for a something to be a “Success,” all of its children must also be a “Success.”
Here is what each status value means, listed in order of increasing priority:
| Value | Description |
|---|---|
| Success | This task’s desired state is met. |
| Pending | Services haven’t started executing this task. |
| Unresponsive | The service responsible for this task seems to be unresponsive. |
| Processing | A service is actively working on this task. |
| Error | When a service was working on this task, it failed. |
| Undefined | If you see this, there’s a bug in the implementation. |
Continuous Monitoring
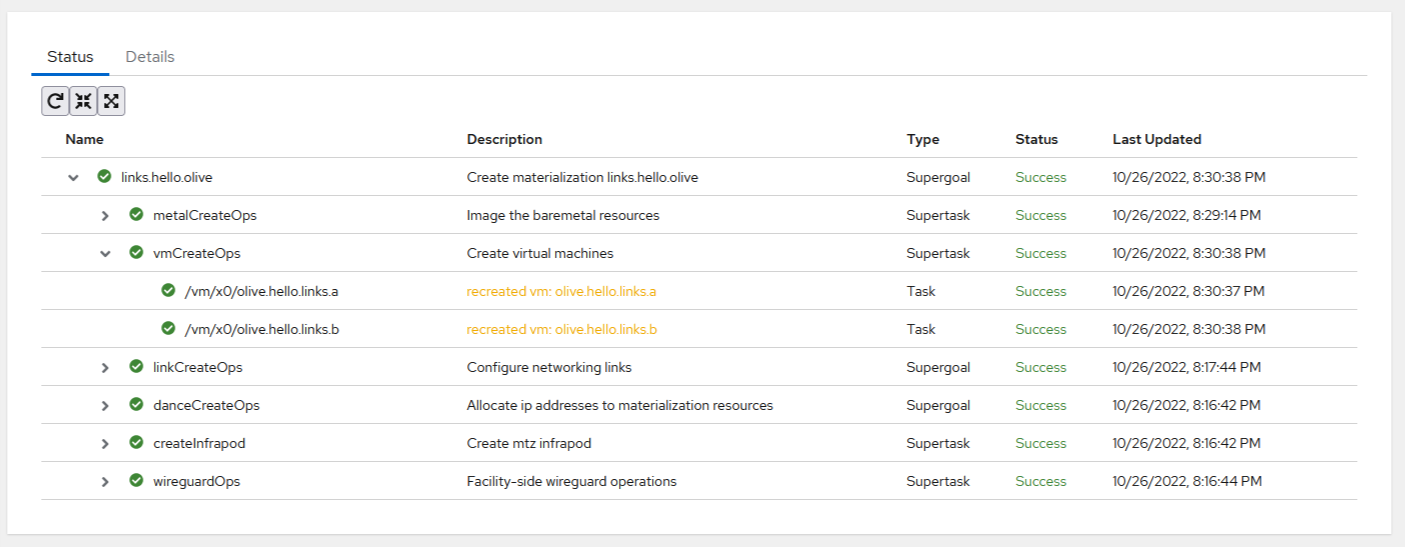
To a limited degree, some statuses are not just posted once, but are also continuously monitored to ensure that the desired state is still met.
Currently, only the vmCreateOps and createInfrapod goals currently have their tasks continuously monitored.
If there are issues, it will try to redo those tasks so that the desired state is met. If it recovers, you’ll see a warning message that something had to be fixed:
Final Notes
This implementation isn’t complete (you can check out its current limitations here) but even in its current state, it’s already incredibly useful.
Definitely let us know if you unexpectedly see Unresponsive, Error, or Undefined.
Unresponsive in particular has the potential to be actively affecting other users!
Implementation Deep Dive
Why status was missing
One major feature absent from the initial MergeTB 1.0 is viewing the status of a materialization. This is partly a result of the new reconciler architecture design.
The reconciler architecture design is summarized as follows: instead of a centralized system that runs every task when needed, you have a distributed system where you write the desired state into a shared database, and let individual microservices perform whatever tasks they need to do to accomplish the desired state.
In our implementation, what this means is that a user’s request gets sent to an API server, that request becomes codified as the desired state, and we let individual microservices figure what they should do.
This allows us to limit the complexity of any specific microservice – it only needs to do what it needs to do and nothing else. Unless it has a dependency, it does not need to know about other services and other services do not need to know about it.
This reconciler archtecture also tends to be lot more robust to failures and restarts – whenever an individual microservice restarts, it can just pick up where it left off, instead of a centralized service having to figure the totality of what’s wrong and how to recover. It also lends itself well to horizontal scaling, due to the inherent distributed model of computation.
While the reconciler model improves scalability and resilience, it also makes tracking task status more difficult, due to the inherent asynchronous and partitioned nature of architecture. As an example, the API server does not directly handle requests, it only writes what needs to be done. This also means that the API server does not directly know how tasks are accomplished, or even when tasks are accomplished. Going further, this also means that the API server does not even know which microservice actually handles a specific task. It doesn’t even know what other microservices even exist!
As such, it’s little tricky to directly get the status of a task from a microservice if you:
- Don’t know what other microservices even exist
- Don’t know how to contact another microservice
- Don’t know which microservice is supposed to handle a given task
Note that this can get especially tricky when individual tasks have dependenices on other microservices.
Although you could codify all of this information, it would be a giant, unmaintainable mess, and would end up negating the “partioned” aspect of the reconciler architecture.
What we did without status
Outside of it being unknown for users to know if their materialization is up or not, the lack of visibility into the system also causes major operational headaches. When a user reports a problem (like they’re complaining that they cannot connect to a node) where do you start looking? Since this end result (being able to connect to a node) is dependent on a whole host of subtasks being accomplished, we would manually comb through the logs until we found something unexpected.
And there are a lot of logs to look through.
Was the networking not set up correctly? That would be the canopy service. But on which host did the canopy service fail on? The entire path of links need to be set up. If the networking failed, did it prevent the nodes from being able to network boot? Time to check the logs of the sled service. Or what if we failed to create the services to allow network booting? Time to check the logs of the infrapod container. Or maybe they were able to get to network boot, but they’re hanging for whatever reason when we stamp the image? That would be the sled service.
This isn’t great, to say the least.
How we’re getting status
So, as we’ve written earlier, communicating with a microservice directly is a no go. Instead, we have microservices passively record what they’ve been doing in a shared, distributed database so we can grab it later as needed.
Whenever a service handles a task, we have them record that they handled the task in a distributed database. The recorded information includes:
- Their name
- The task they handled
- What happened when handling the task
- Any subtasks that it created to do its task
- Metadata (like when it was handled, etc.)
So, to get the status of an individual task, we just have to look for messages that correspond to the task and its potential subtasks.
As the API service knows what tasks need to be accomplished to perform a goal (because it wrote the tasks in the first place), we can also have it record the tasks that it wrote for a specific goal.
Then, to get a status of a larger goal, we just have to iterate through the list of tasks that belong to that goal.
(That list is missing for old materializations, which is why you can’t get a status tree for them. In principle, that information can be reconstructed, but it’s a fair amount of complexity for a small transitional period.)
For organizational purposes, these tasks are usually grouped into sub-goals, but this is not required.
We’ve implemented this at the reconciler package level, so every reconciler that we write automatically has status built-in.
Status Validity
So, if you just read the status, how do you know that the status value present is actually correct?
For example, if a reconciler is down, it can’t update any of its statuses. If the last thing it did was handle a task successfully, but the task has been updated while the reconciler is down, then the status isn’t actually Success, but actually Pending.
So, there are additional things to check than just the status message when reading statuses:
- The actual task data and its metadata
- If the status message’s task data and metadata does not match the last reconciled task data and metadata, then its status value is irrelevant, and should be Pending.
- If the reconciler seems to be down, the status value may or may not be relevant, but should be noted as Unresponsive.
- This “may or may not be relevant” property means that the user should see Unresponsive, but the reconciler should see whatever it last wrote down when determining what it should do.
Another example of a status validity failure is that the reconciler did something, but for whatever reason, it fell over. A concrete example of this is that “just because you started up the VM in the past, doesn’t means the VM is still currently up.”
So, a notion of continuous monitoring is neccessary for status validity. This is implemented on the package level by allowing reconcilers to opt-in to periodic check-ins of tasks, defined by the specific implementation. The opt-in nature of it is because few of our reconcilers have something implemented that meet the requirements for periodic check-ins to properly work. The idea is that eventually, everything that needs periodic check-ins has them.
Etcd Implementation Notes
It’s pretty common for a materialization to span 100’s of keys since there’s a lot of configuration and work that needs to be done. Reading only 1 status at a time then had large latency concerns and even was able to take down Etcd, the default key/value store we use, in our Virtual Test Environment. (By the way, taking down Etcd causes a lot of problems.)
As a result of this, how we interface with Etcd needed to be reworked a little bit. The main storage package that we had only let you read or write 1 complex object at a time, where “complex” means that its reads or writes requires reading more than 1 object. As status objects need to read a few other objects to ensure their validity, our main storage package had to be extended a bit so that we can read and write multiple complex objects at a time.
Current Limitations and Concerns
No Foundry Status
One of the limitations of the current status implementation is that it assumes that the keys and statuses are all in the same distributed database.
Unfortunately, this isn’t entirely true – Foundry, our image configuration service, writes its information into the materialization-specific database.
This is done because if foundry had access to the facility-wide database, that means the user has access to it, which is very, very dangerous, as the facility-wide database is considered to be the ground truth for all other materializations as well.
Also, foundry doesn’t operatate in a reconciler way right now, so there’s no compatible status messages to begin with. As a result of these two things, the current status implementation does not get foundry status, so the materialization may not be quite ready for users even if the status says “Success” for the materialization.
No Continuous Monitoring for Network Configuration
Although we have a service that can configure networking on a machine or switch, we don’t have well tested code that checks if the current network configuration is acceptable.
Unfortunately, checking if the current network configuration is the “correct” network state is a little bit tricky, becase there’s wiggle room in network configurations that work. Sometimes, the MAC address or interface needs to be a specific value. Sometimes, they can be any value. So, just plain equality across each field does not work.
Multiply this across the number of basic network interface types (VXLAN, VTEP, Physical Port, BGP peer, etc.) and you can see how it starts to get pretty tricky.
You also have to really make sure that this is precisely correct, otherwise experiments will get affected by the periodic reinitialization of the interfaces.
There’s also a related notion of continuous monitoring of network connectivity and performance that is not implemented either, which is definitely complicated enough on its own.
No Status Implementation For The Deletion of Objects
Cleaning up something is itself a task, but there’s no current way to get the status of cleaning something up because of the way that we indicate we should clean something up.
To mark that we should clean something up, we delete the task, which leaves questions on when the statuses and the list of subtasks should be deleted.
As currently implemented, everything is cleaned up as soon as possible, so there’s nothing for the user to read, whether a status or a list of subtasks.
Lots and lots of keys
On the facility side, we use an Etcd key for a lot of individual tasks, like individual VMs and DNS entries for each node. This means at minimum, we’re reading 4N keys to read a status tree for a materialization, where N is the number of nodes:
- There are 2 task keys per node: 1 for the node itself, 1 for its infranet DNS entry
- For each task key, to read its status, we need to read at least 2 keys: its status key and the task key.
- (The key that we use to see if a reconciler is responsive or not is often shared between task keys, so this is a constant factor.)
For materializations greater than 4000 nodes, it’s possible that the status tree for a materialization exceeds the GRPC limits and then the user can’t get the status of it. Also, it can be a lot of data, for both etcd to handle and to transfer to the user. Every time the status is requested, it is re-computed from all of the individual tasks, so we have to get all of the keys every time.
Networking may also have a lot of keys, but that’s obviously dependent on the specific materialization.
A potential solution is to have the mega-DNS configuration file per materialization and a mega-VM configuration file per host/materialization instead stored in Minio (our large object store). It’s also possible to apply this idea to networking, if needs be as well.
Status tree caching is also an option to limit etcd reads as well, but that can easily get complicated.
A Successful Task Tree Is Theoretically Not Complete
Note in this implementation, we still don’t know don’t know which microservice is supposed to handle a given task. This has been sidestepped because trivially we know if no microservices have handled the task, then the task isn’t handled.
But what happens if the task needs to be handled by more than 1 microservice? It’s possible then, that when getting the status tree that all found tasks report “Success,” but there are unresponsive reconcilers who didn’t see the key, so they haven’t written any status messages for us to find.
In other words, if a task is handled by more than 1 reconciler, if one of those reconcilers are down and they have no pre-existing status messages, the fact that they’re down will be ignored when computing the status tree.
Practically speaking, this isn’t currently an issue on the facility side. The only tasks handled by more than 1 reconciler have the prefix /metal/*, since those are used by the metal service (which reboots nodes) and the sled service (which stamps images onto baremetal nodes). However, both of those reconcilers are used to initialize the testbed, so should have status keys by the time a user materializes something onto the testbed.